



Meta-World is an open-source simulated benchmark for meta-reinforcement learning and multi-task learning consisting of 50 distinct robotic manipulation tasks.
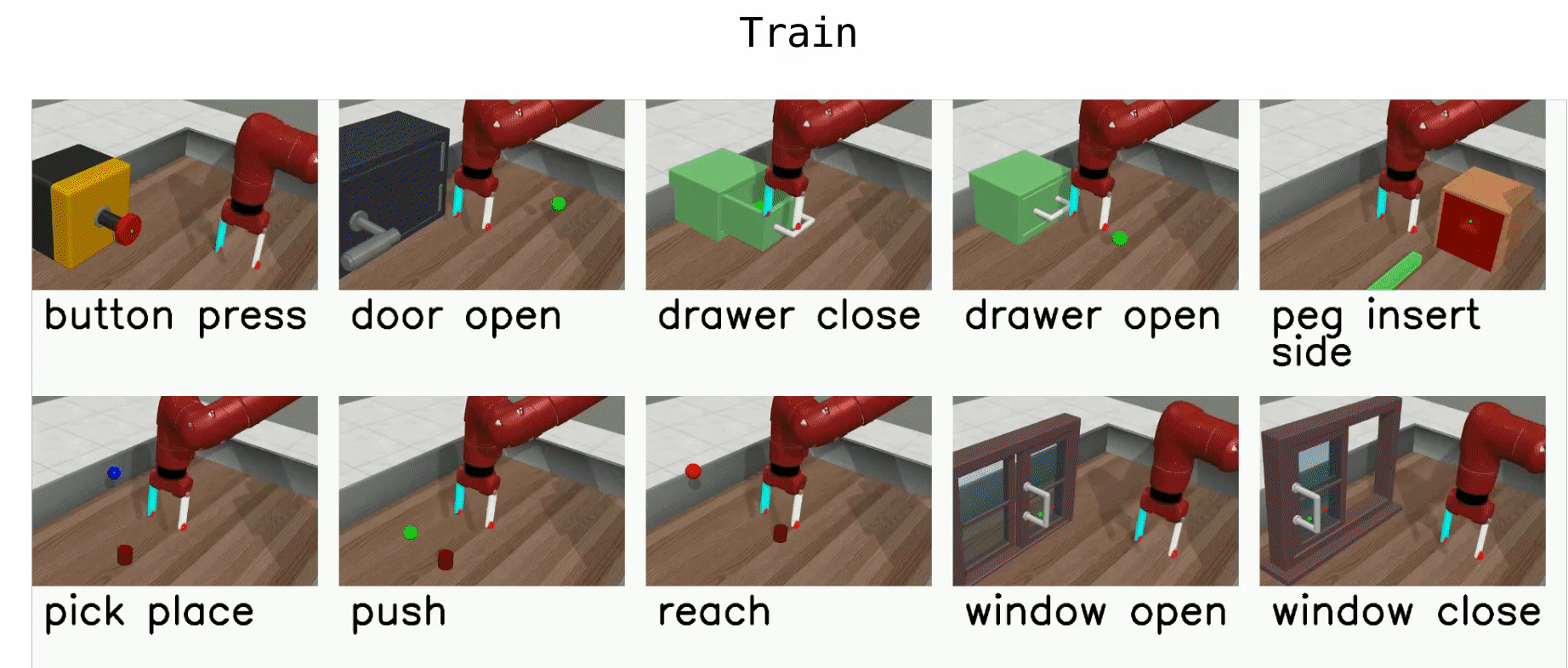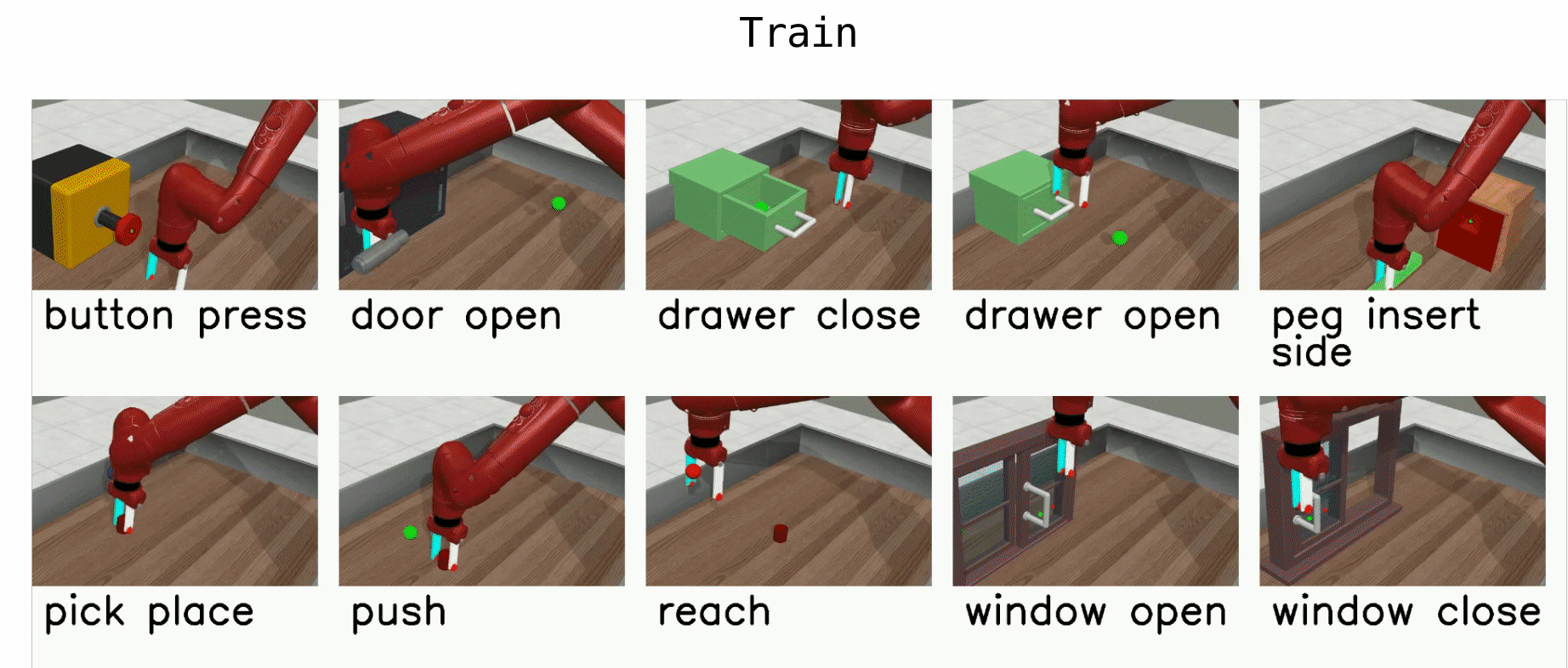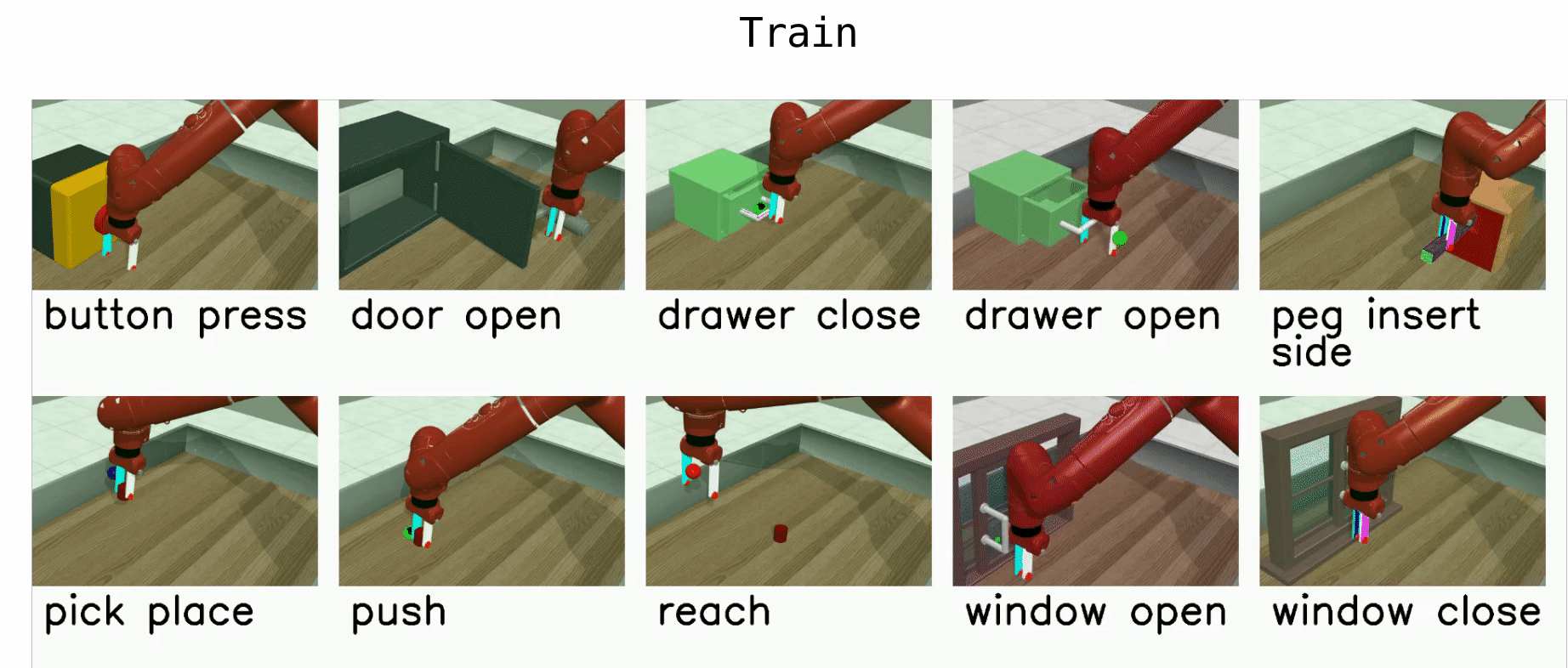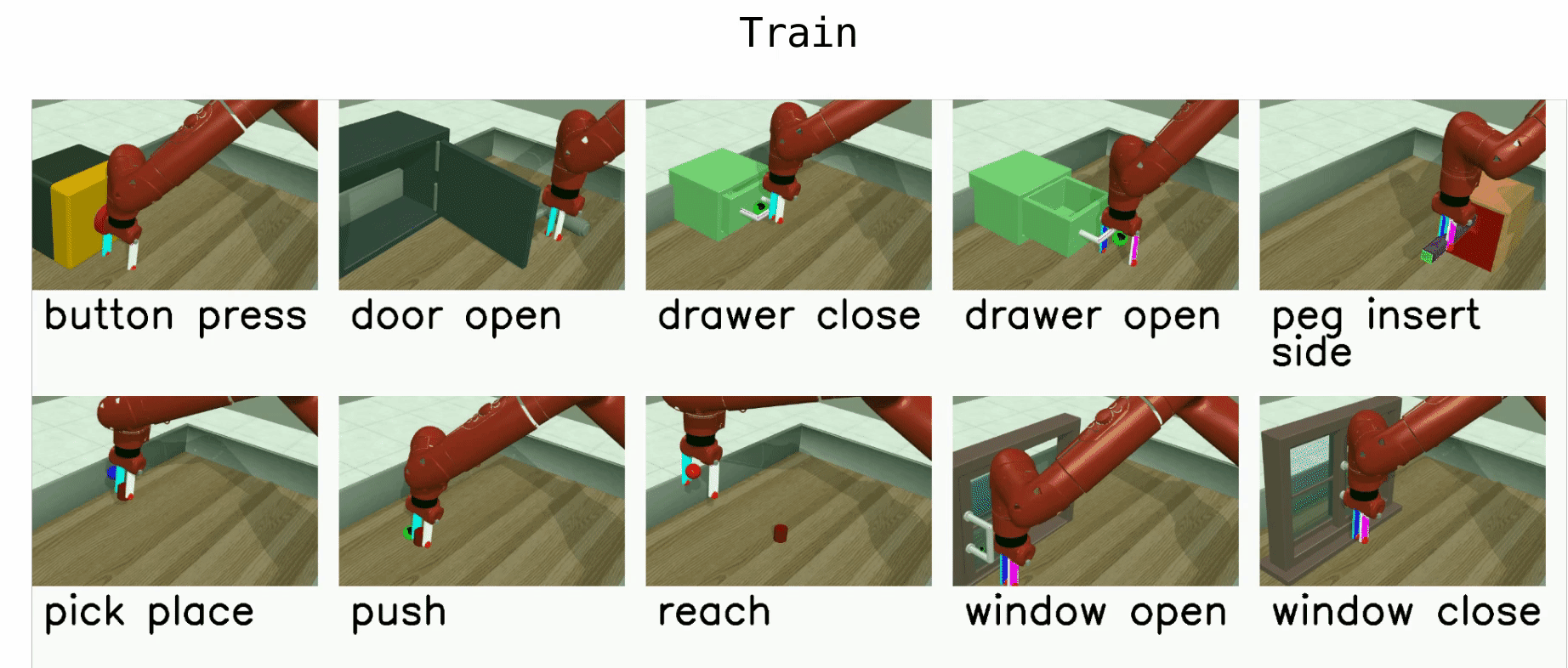
Basic example:
import gymnasium as gym
import metaworld
env = gym.make('Meta-World/MT1', env_name='reach-v3')
obs = env.reset()
a = env.action_space.sample()
next_obs, reward, terminate, truncate, info = env.step(a)