


Benchmark Descriptions¶
The benchmark provides a selection of tasks used to study generalization in reinforcement learning (RL). Different combinations of tasks provide benchmark scenarios suitable for multi-task RL and meta-RL. Unlike usual RL benchmarks, the training of the agent is strictly split into training and testing phases.
Multi-Task Problems¶
The multi-task setting challenges the agent to learn a predefined set of skills simultaneously. Below, different levels of difficulty are described.
Multi-Task (MT1)¶
In the easiest setting, MT1, a single task needs to be learned where the agent must, e.g., reach, push, or pick place a goal object. There is no testing of generalization involved in this setting.
Multi-Task (MT10)¶
The MT10 evaluation uses 10 tasks: reach, push, pick and place, open door, open drawer, close drawer, press button top-down, insert peg side, open window, and open box. The policy should be provided with a one-hot vector indicating the current task. The positions of objects and goal positions are fixed in all tasks to focus solely on skill acquisition.
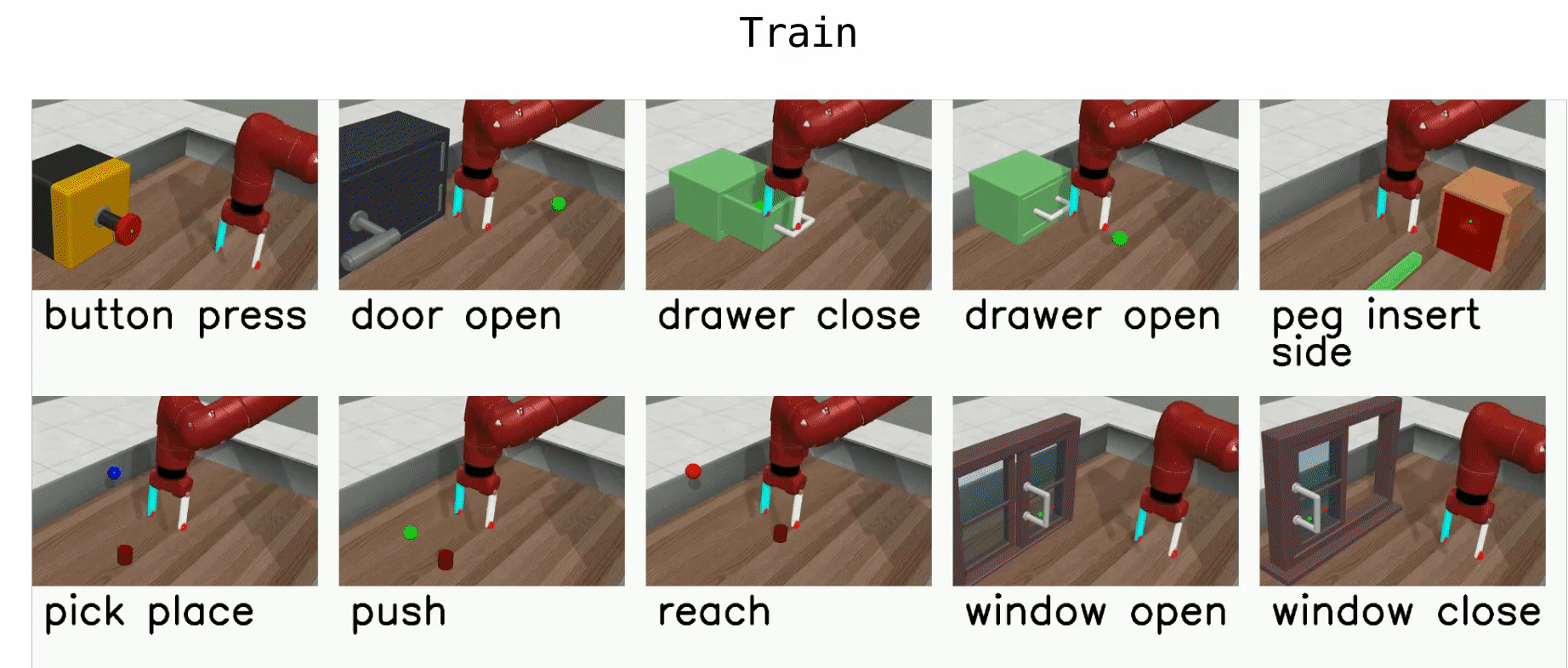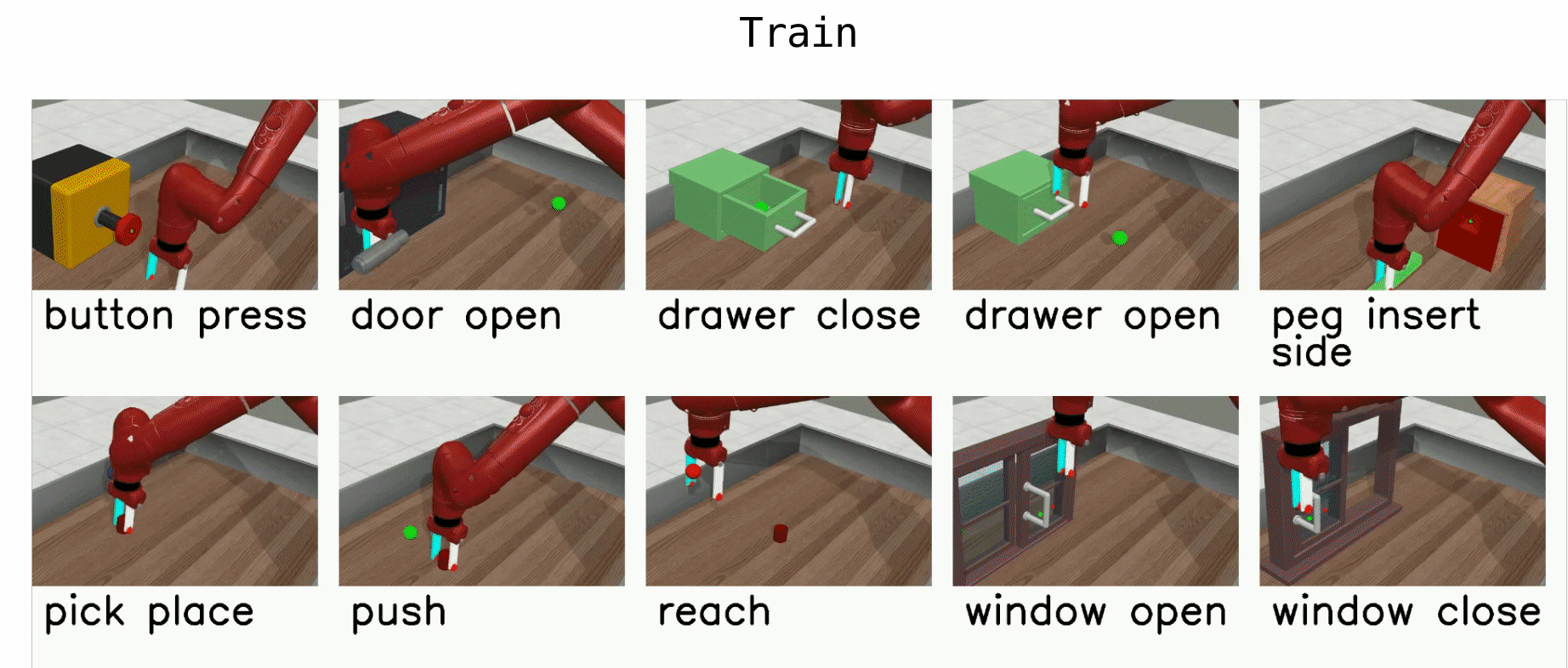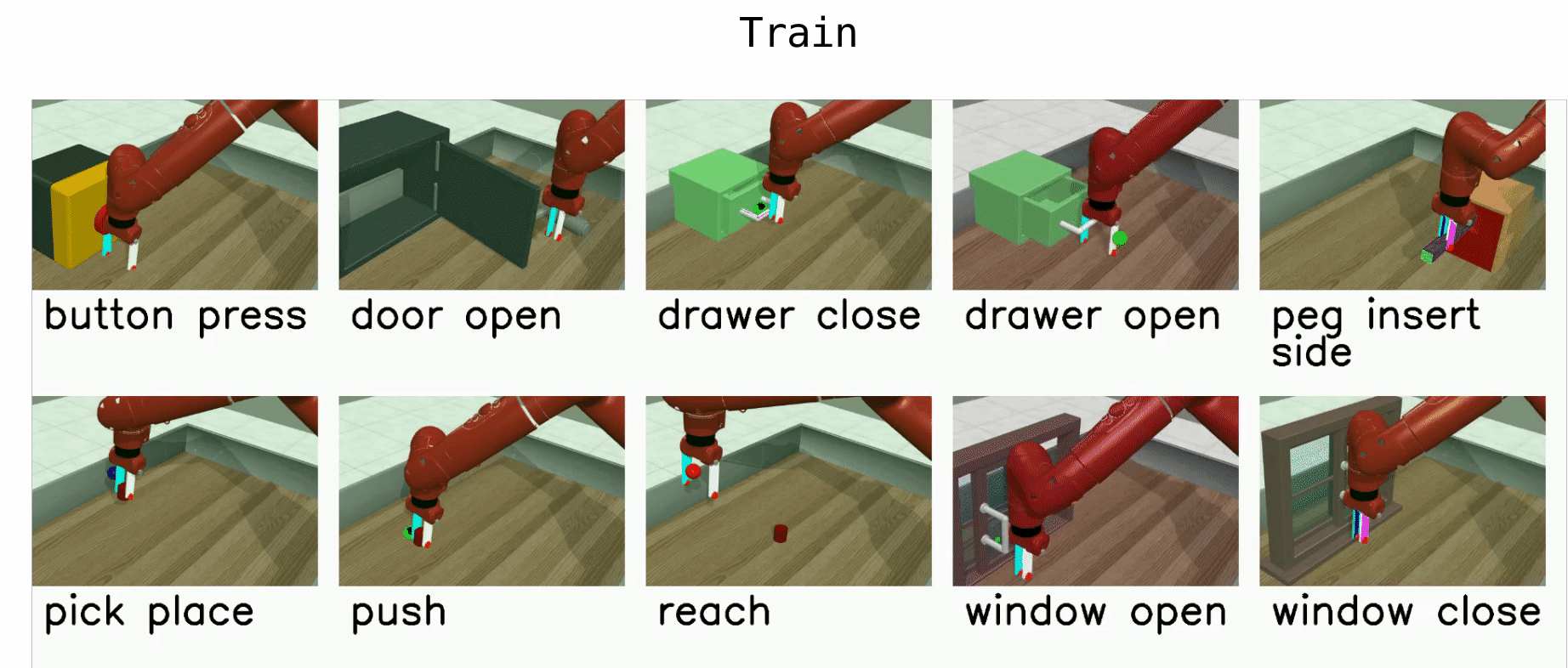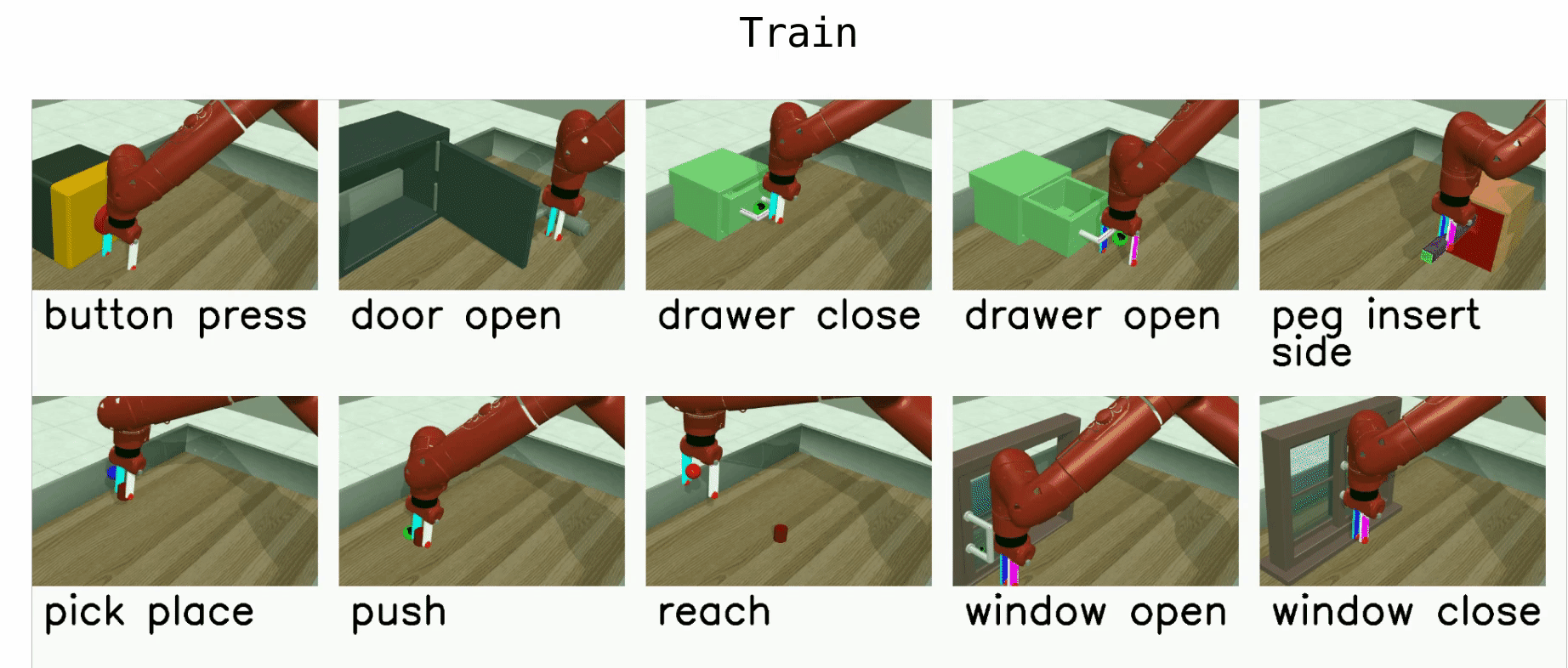
Multi-Task (MT50)¶
The MT50 evaluation uses all 50 Meta-World tasks. This is the most challenging multi-task setting and involves no evaluation on test tasks. As with MT10, the policy is provided with a one-hot vector indicating the current task, and object and goal positions are fixed.
See Task Descriptions for more details.
Meta-Learning Problems¶
Meta-RL attempts to evaluate the transfer learning capabilities of agents learning skills based on a predefined set of training tasks, by evaluating generalization using a hold-out set of test tasks. In other words, this setting allows for benchmarking an algorithm’s ability to adapt to or learn new tasks.
Meta-RL (ML1)¶
The simplest meta-RL setting, ML1, involves few-shot adaptation to goal variation within one task. ML1 uses single Meta-World Tasks, with the meta-training “tasks” corresponding to 50 random initial object and goal positions, and meta-testing on 10 held-out positions. We evaluate algorithms on three individual tasks from Meta-World: reaching, pushing, and pick and place, where the variation is over reaching position or goal object position. The goal positions are not provided in the observation, forcing meta-RL algorithms to adapt to the goal through trial-and-error.
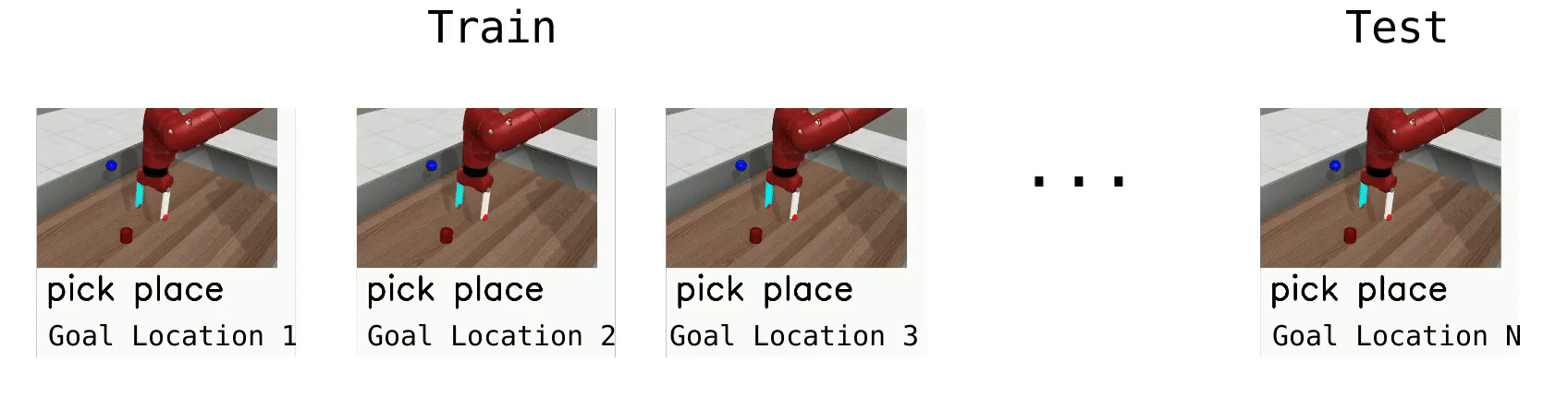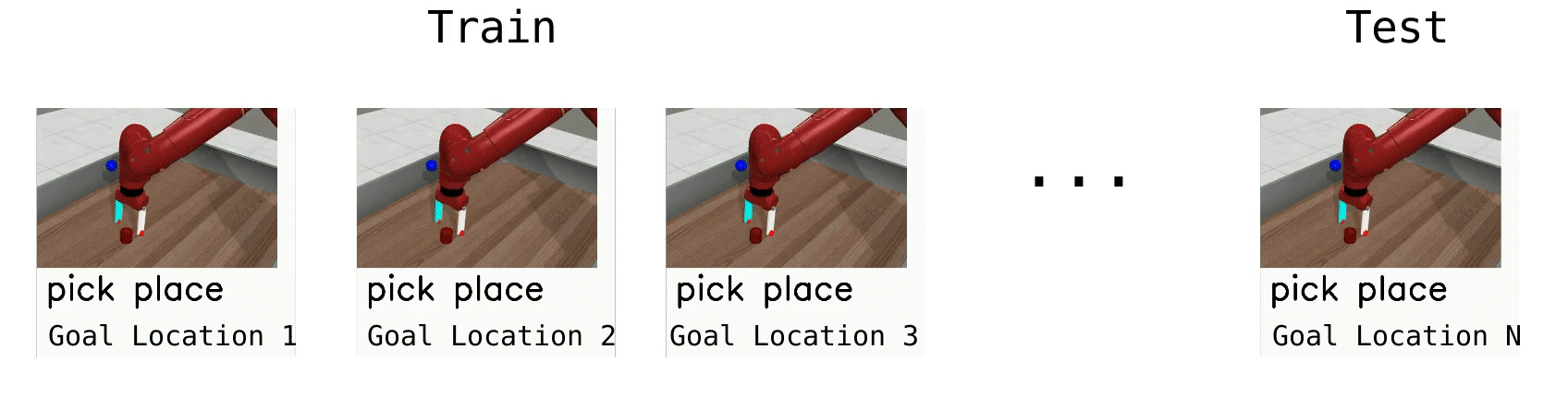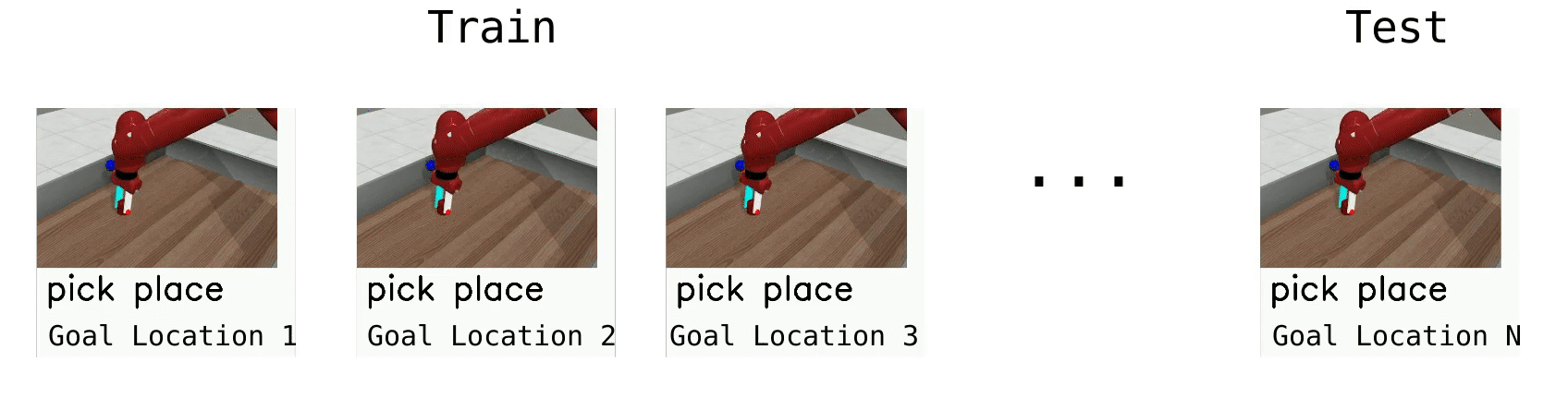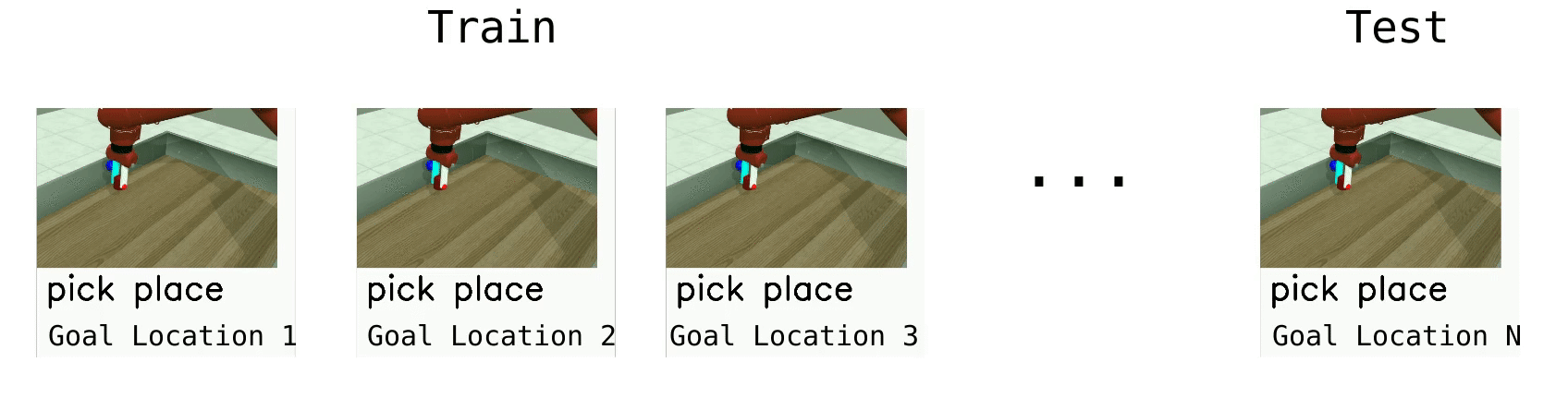
Meta-RL (ML10)¶
The ML10 evaluation involves few-shot adaptation to new test tasks with 10 meta-training tasks. We hold out 5 tasks and meta-train policies on 10 tasks. We randomize object and goal positions and intentionally select training tasks with structural similarity to the test tasks. Task IDs are not provided as input, requiring a meta-RL algorithm to identify the tasks from experience.
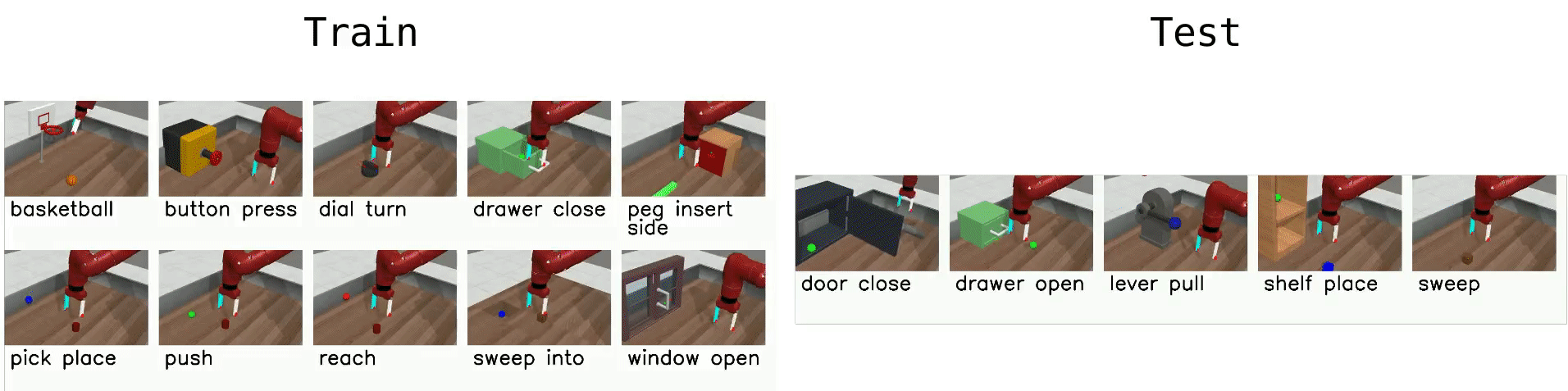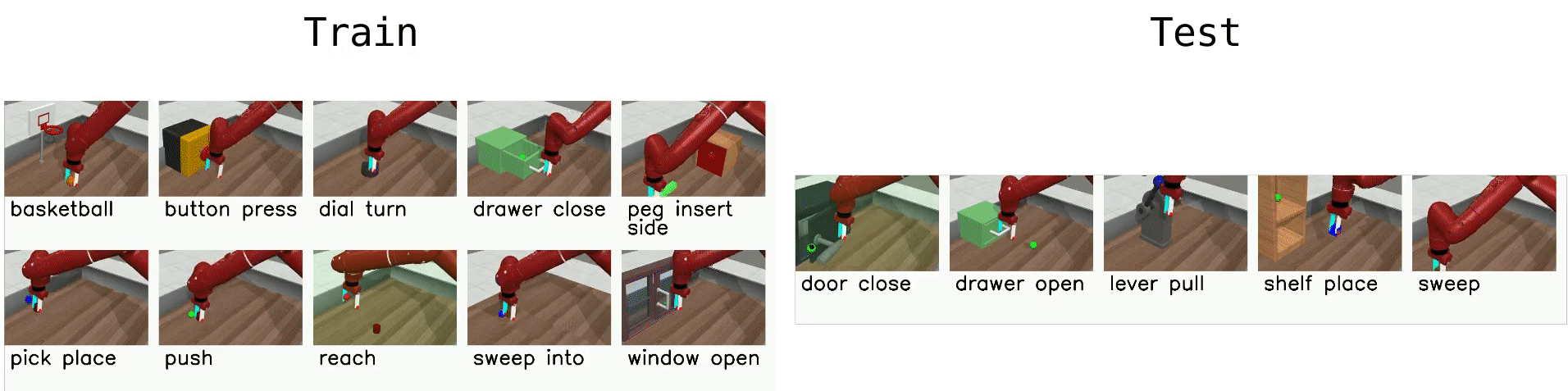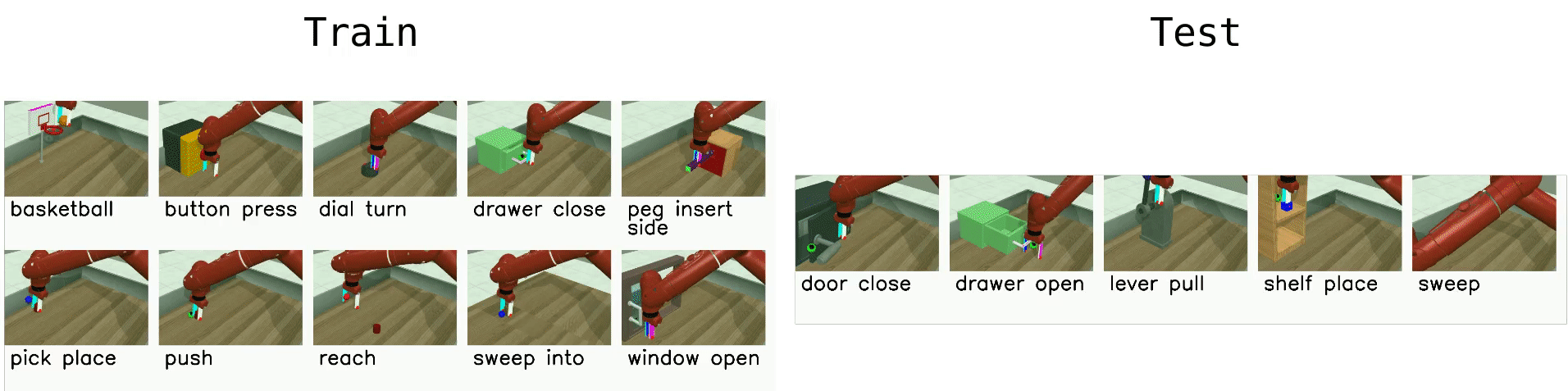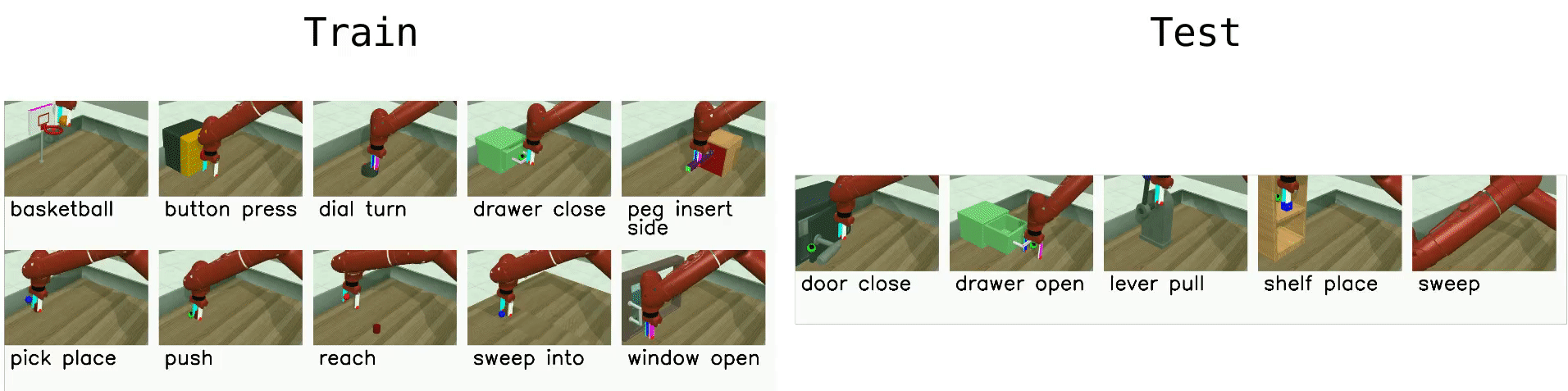
Meta-RL (ML45)¶
The most difficult environment setting of Meta-World, ML45, challenges the agent with few-shot adaptation to new test tasks using 45 meta-training tasks. Similar to ML10, we hold out 5 tasks for testing and meta-train policies on 45 tasks. Object and goal positions are randomized, and training tasks are selected for structural similarity to test tasks. As with ML10, task IDs are not provided, requiring the meta-RL algorithm to identify tasks from experience.
